




Notebooks

Categories



Cells
Premium


BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.
BioTuring
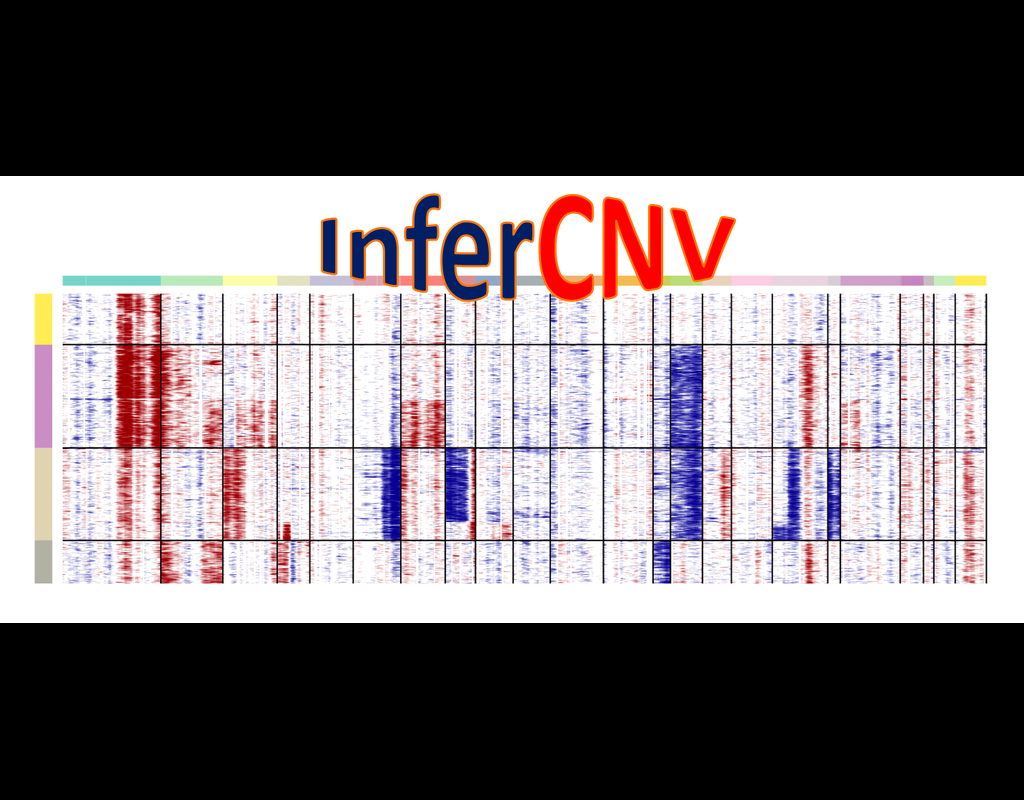
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
BioTuring
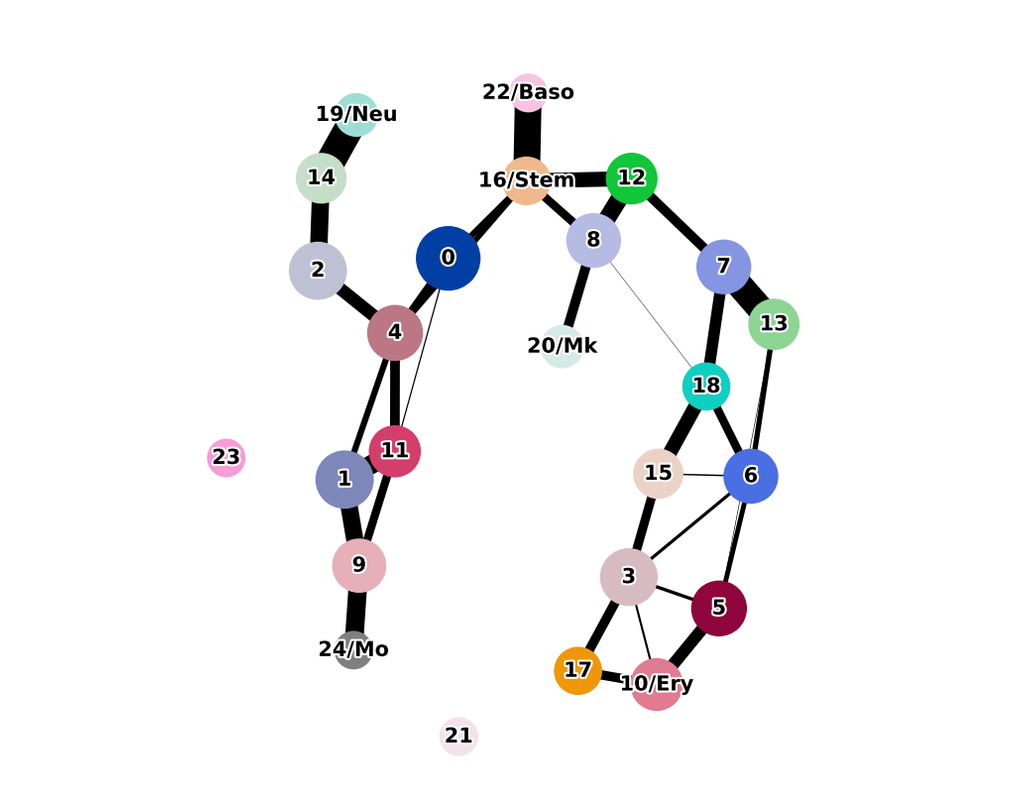
Mapping out the coarse-grained connectivity structures of complex manifolds
Biological systems often change over time, as old cells die and new cells are created through differentiation from progenitor cells. This means that at any given time, not all cells will be at the same stage of development. In this sense, a single-cell sample could contain cells at different stages of differentiation. By analyzing the data, we can identify which cells are at which stages and build a model for their biological transitions.
By quantifying the connectivity of partitions (groups, clusters) of the single-cell graph, partition-based graph abstraction (PAGA) generates a much simpler abstracted graph (PAGA graph) of partitions, in which edge weights represent confidence in the presence of connections.
In this notebook, we will introduce the concept of single-cell Trajectory Analysis using PAGA (Partition-based graph abstraction) in the context of hematopoietic differentiation.
BioTuring
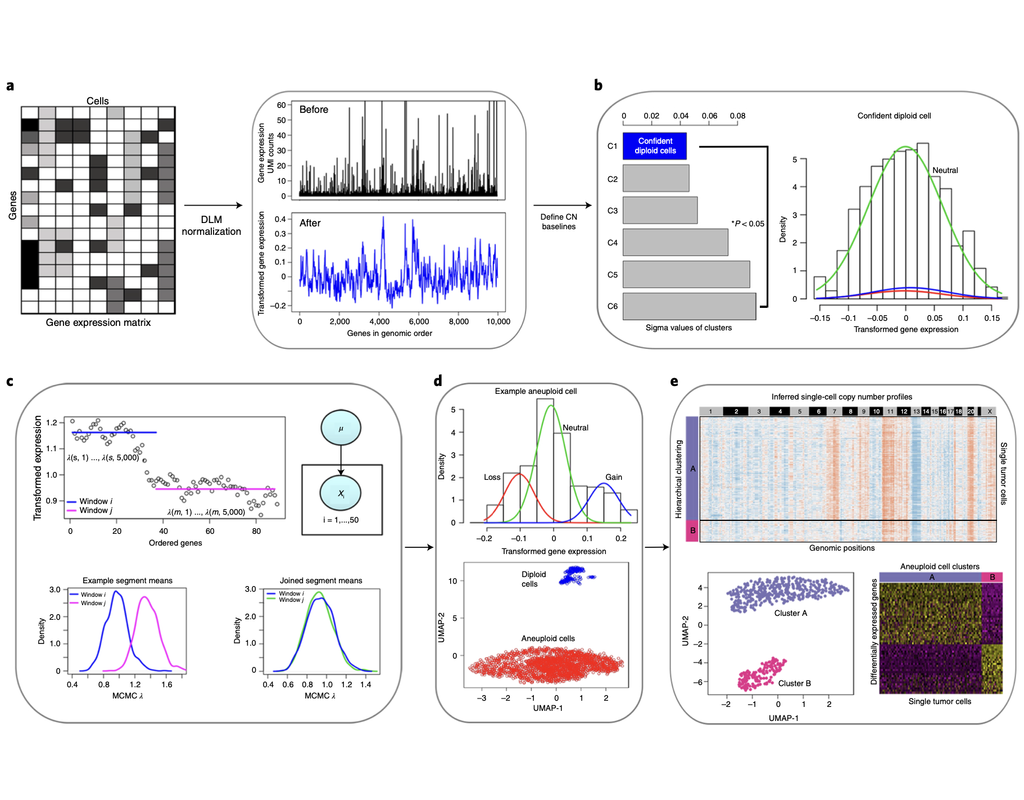
Classification of tumor and normal cells in the tumor microenvironment from scRNA-seq data is an ongoing challenge in human cancer study.
Copy number karyotyping of aneuploid tumors (***copyKAT***) (Gao, Ruli, et al., 2021) is a method proposed for identifying copy number variations in single-cell transcriptomics data. It is used to predict aneuploid tumor cells and delineate the clonal substructure of different subpopulations that coexist within the tumor mass.
In this notebook, we will illustrate a basic workflow of CopyKAT based on the tutorial provided on CopyKAT's repository. We will use a dataset of triple negative cancer tumors sequenced by 10X Chromium 3'-scRNAseq (GSM4476486) as an example. The dataset contains 20,990 features across 1,097 cells. We have modified the notebook to demonstrate how the tool works on BioTuring's platform.
Trends

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolutio(More)