




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
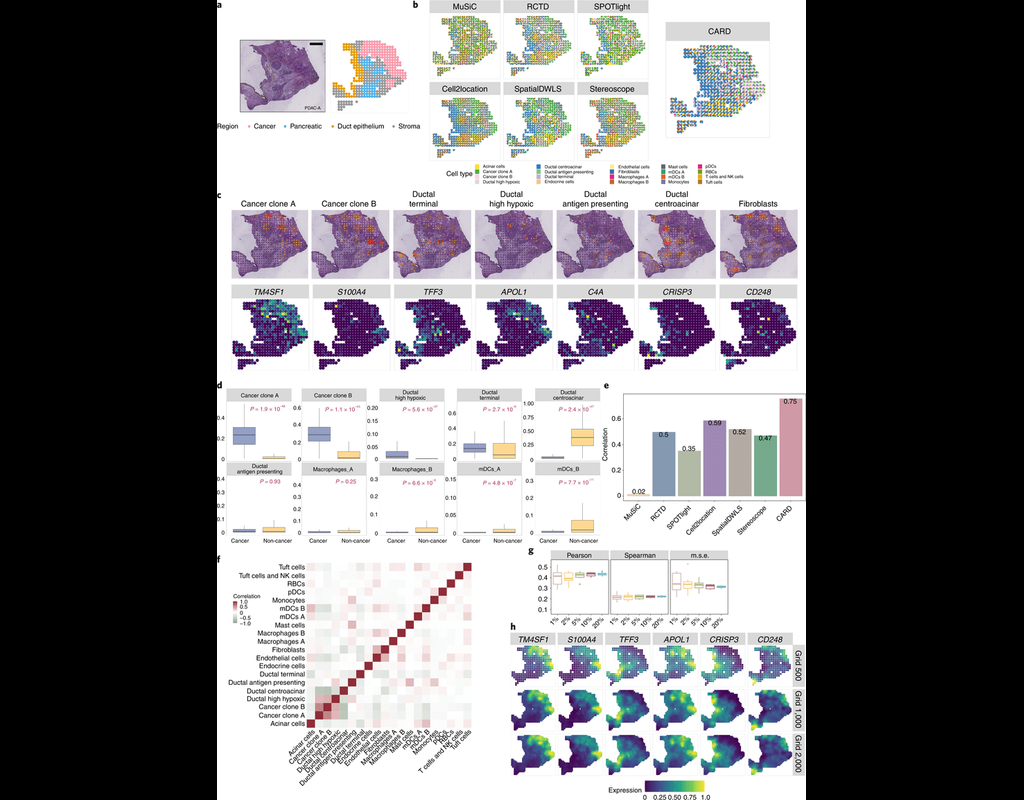
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.
BioTuring
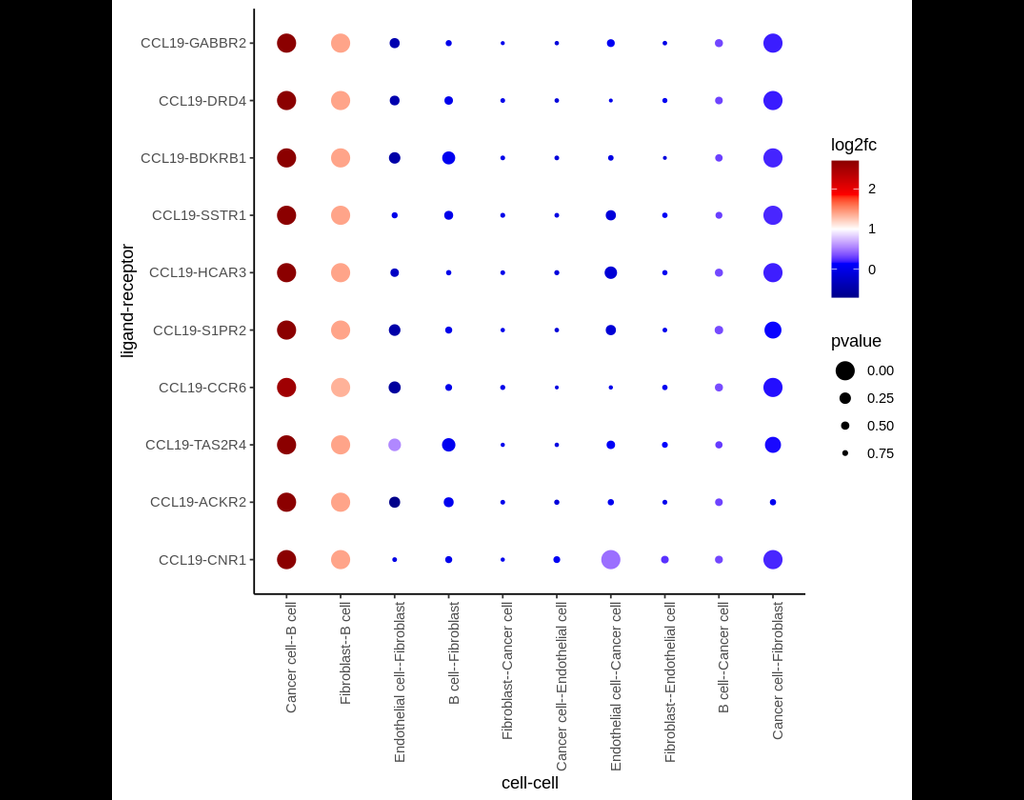
Single-cell RNA data allows cell-cell communications (***CCC***) methods to infer CCC at either the individual cell or cell cluster/cell type level, but physical distances between cells are not preserved Almet, Axel A., et al., (2021). On the other hand, spatial data provides spatial distances between cells, but single-cell or gene resolution is potentially lost. Therefore, integrating two types of data in a proper manner can complement their strengths and limitations, from that improve CCC analysis.
In this pipeline, we analyze CCC on Visium data with single-cell data as a reference. The pipeline includes 4 sub-notebooks as following
01-deconvolution: This step involves deconvolution and cell type annotation for Visium data, with cell type information obtained from a relevant single-cell dataset. The deconvolution method is SpatialDWLS which is integrated in Giotto package.
02-giotto: performs spatial based CCC and expression based CCC on Visium data using Giotto method.
03-nichenet: performs spatial based CCC and expression based CCC on Visium data using NicheNet method.
04-visualization: visualizes CCC results obtained from Giotto and NicheNet.
BioTuring
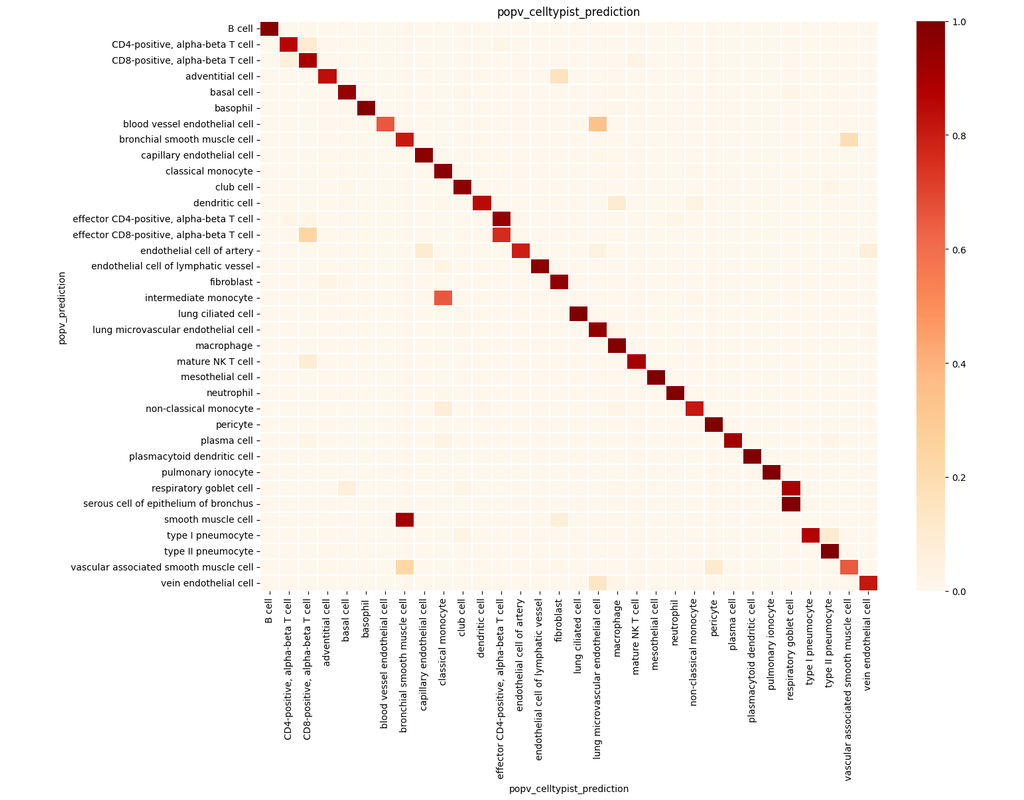
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.
BioTuring
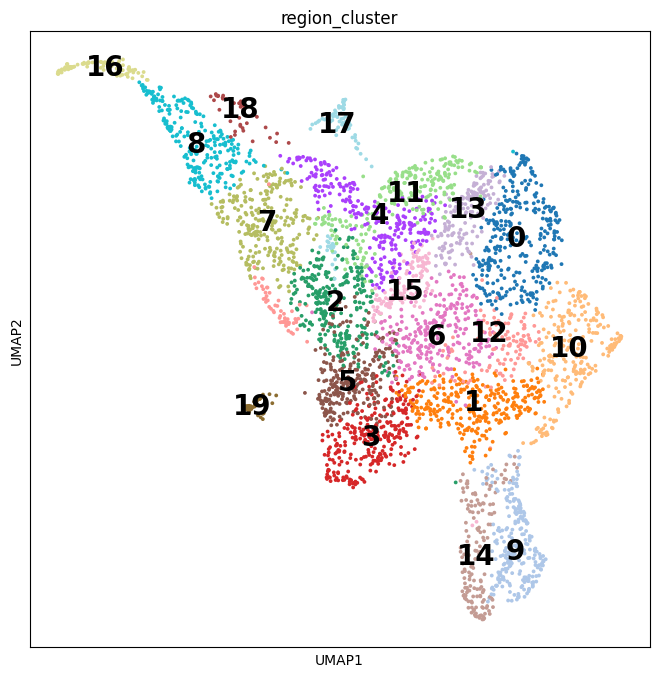
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows statistical strength across locations, thereby enabling the integration of single cell and spatial transcriptomics with higher sensitivity and resolution than existing tools. This is achieved by estimating which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
This tutorial shows how to use cell2location method for spatially resolving fine-grained cell types by integrating 10X Visium data with scRNA-seq reference of cell types. Cell2location is a principled Bayesian model that estimates which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).