




Notebooks

Categories



Cells
Premium


BioTuring
CellRank2 (Weiler et al, 2023) is a powerful framework for studying cellular fate using single-cell RNA sequencing data. It can handle millions of cells and different data types efficiently. This tool can identify cell fate and probabilities across various data sets. It also allows for analyzing transitions over time and uncovering key genes in developmental processes. Additionally, CellRank2 estimates cell-specific transcription and degradation rates, aiding in understanding differentiation trajectories and regulatory mechanisms.
In this notebook, we will use a primary tumor sample of patient T71 from the dataset GSE137804 (Dong R. et al, 2020) as an example. We have performed RNA-velocity analysis and pseudotime calculation on this dataset in scVelo (Bergen et al, 2020) notebook. The output will be then loaded into this CellRank2 notebook for further analysis.
This notebook is based on the tutorial provided on CellRank2 documentation. We have modified the notebook and changed the input data to show how the tool works on BioTuring's platform.
BioTuring
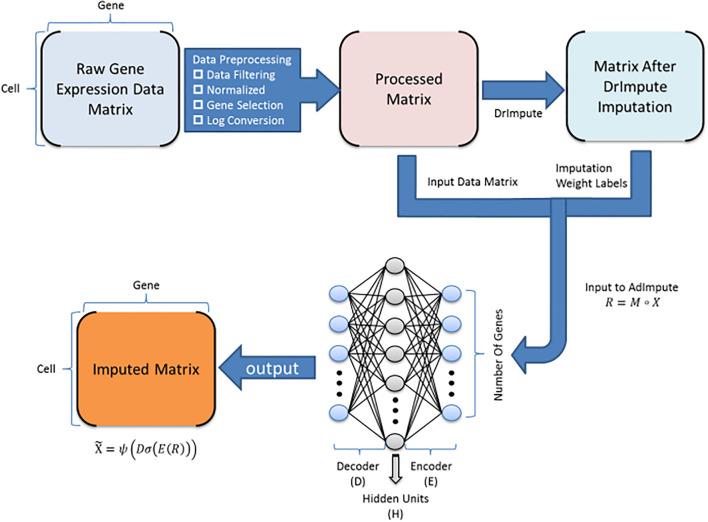
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
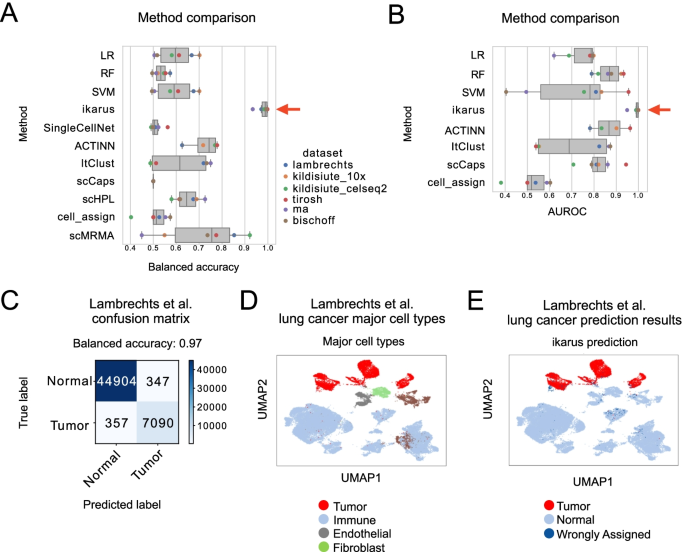
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
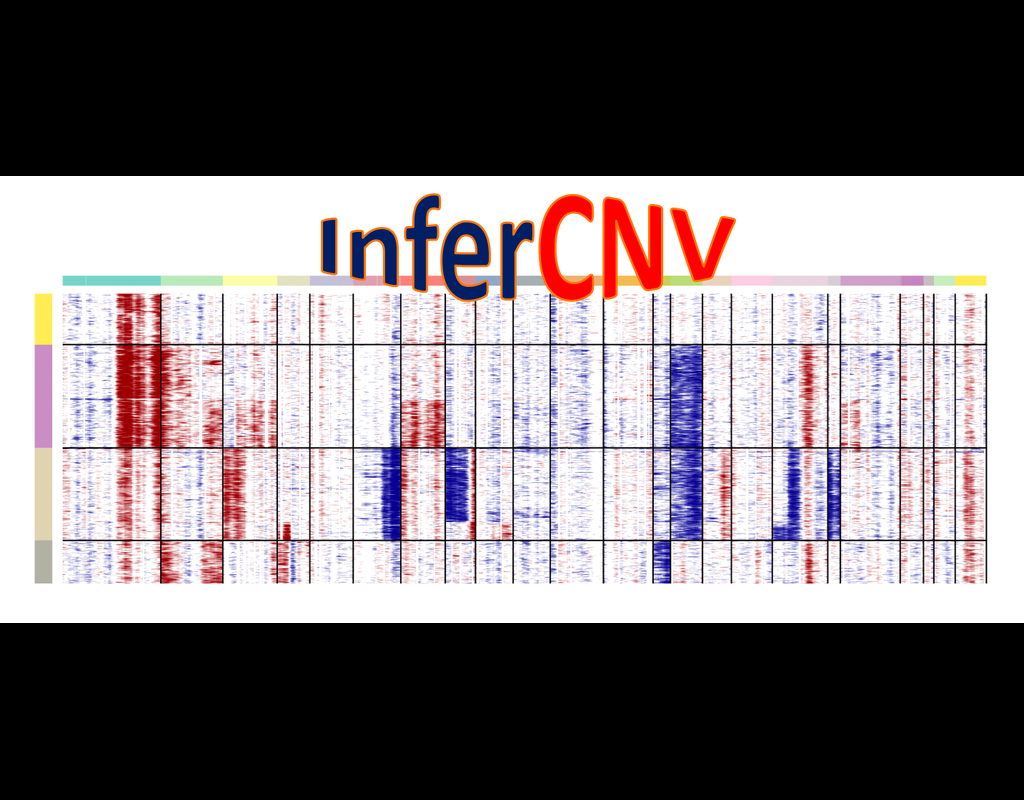
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.
BioTuring
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
Trends

BioTuring
Single-cell data analysis is revolutionizing biological research, but often these dataset sizes can be massive and pose challenges for submission process. Bioalpha-Biocolab addresses this issue by implementing advanced algorithms and leveraging effic(More)