




Notebooks

Categories



Cells
Premium

BioTuring
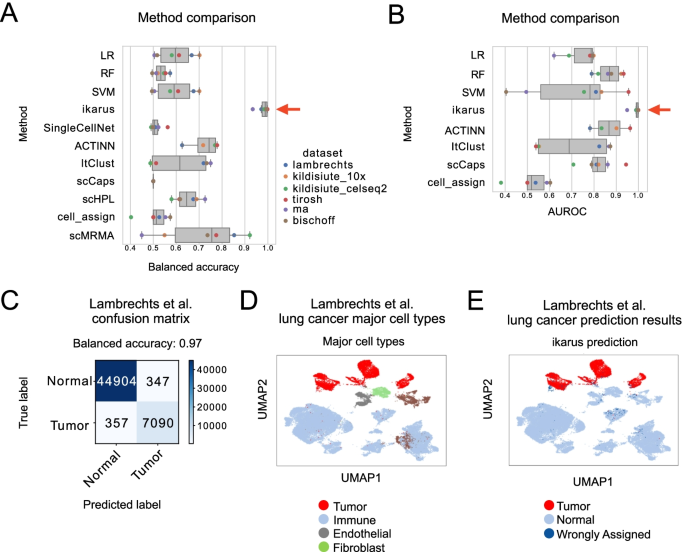
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.

BioTuring
Advances in multi-omics have led to an explosion of multimodal datasets to address questions from basic biology to translation. While these data provide novel opportunities for discovery, they also pose management and analysis challenges, thus motivating the development of tailored computational solutions. `muon` is a Python framework for multimodal omics.
It introduces multimodal data containers as `MuData` object. The package also provides state of the art methods for multi-omics data integration. `muon` allows the analysis of both unimodal omics and multimodal omics.
BioTuring
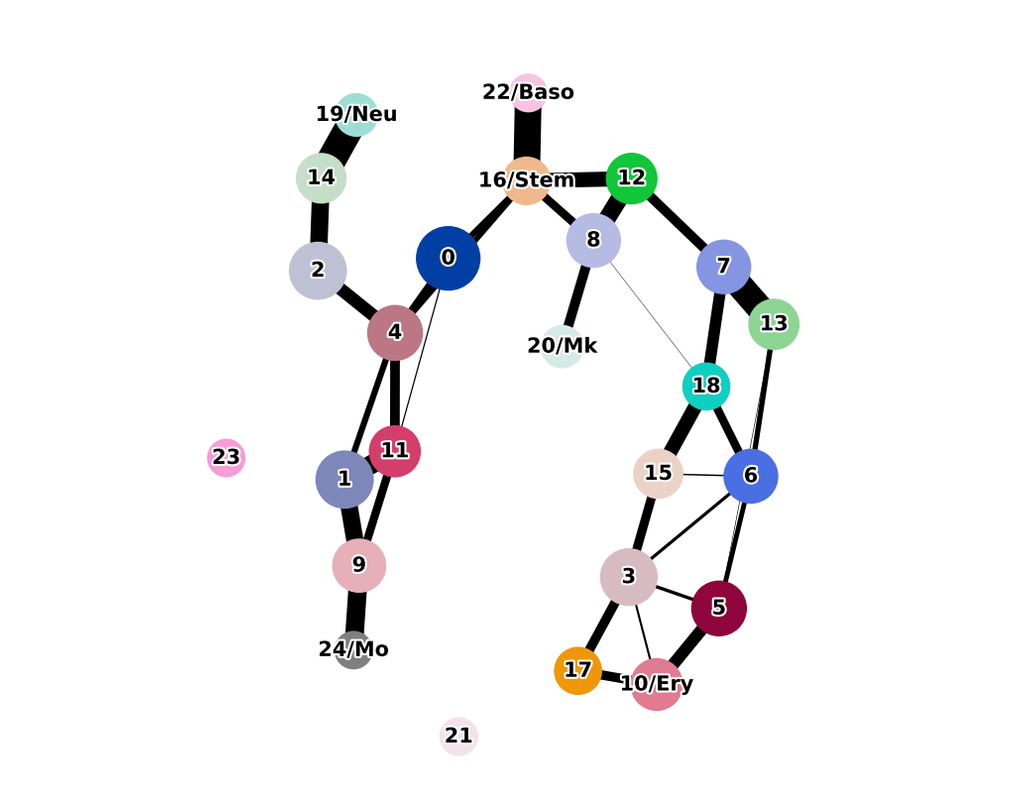
Mapping out the coarse-grained connectivity structures of complex manifolds
Biological systems often change over time, as old cells die and new cells are created through differentiation from progenitor cells. This means that at any given time, not all cells will be at the same stage of development. In this sense, a single-cell sample could contain cells at different stages of differentiation. By analyzing the data, we can identify which cells are at which stages and build a model for their biological transitions.
By quantifying the connectivity of partitions (groups, clusters) of the single-cell graph, partition-based graph abstraction (PAGA) generates a much simpler abstracted graph (PAGA graph) of partitions, in which edge weights represent confidence in the presence of connections.
In this notebook, we will introduce the concept of single-cell Trajectory Analysis using PAGA (Partition-based graph abstraction) in the context of hematopoietic differentiation.
BioTuring
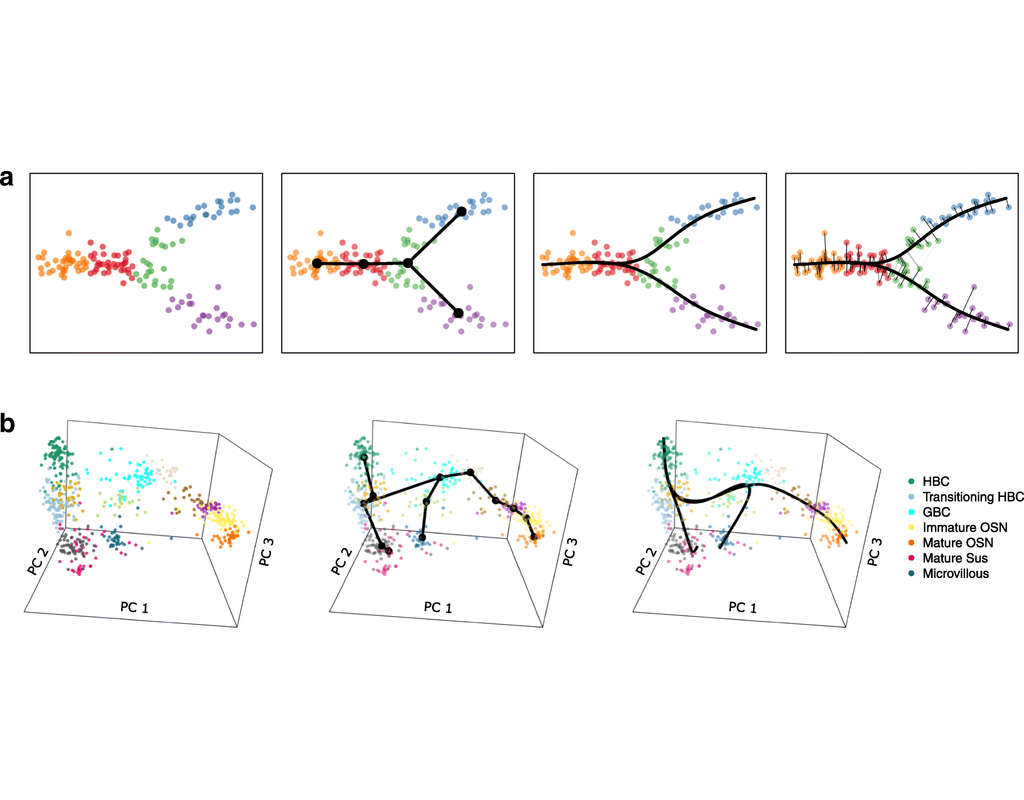
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.
Trends
BioTuring
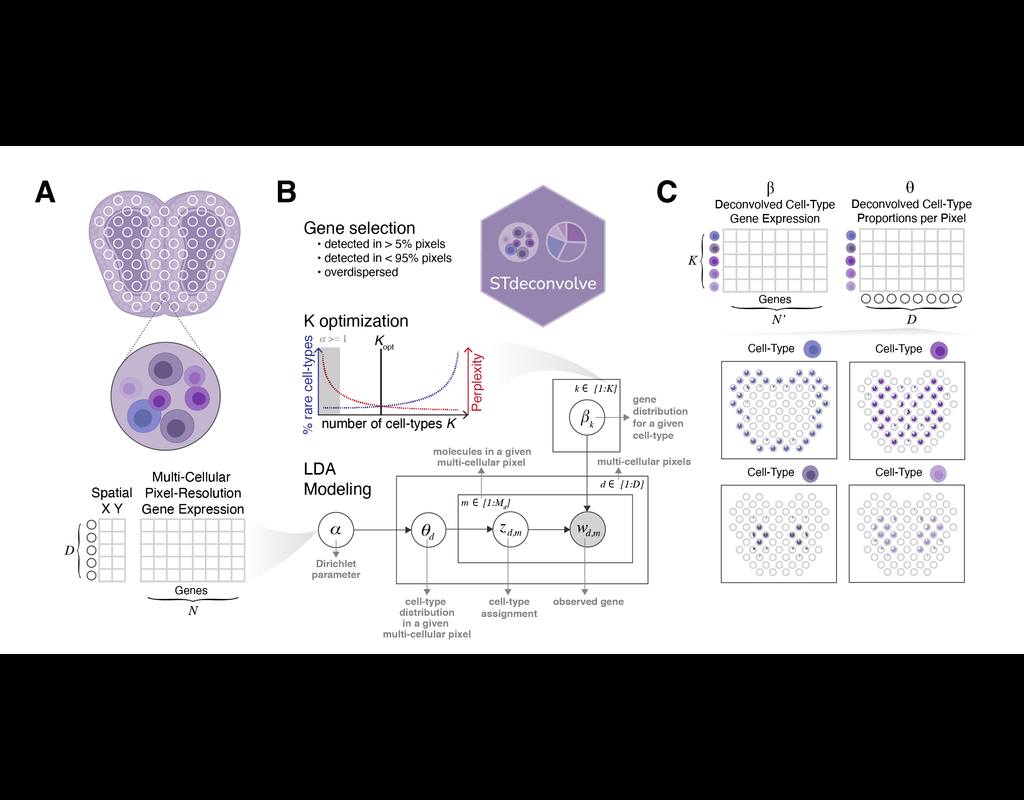
Recent technological advancements have enabled spatially resolved transcriptomic profiling but at multi-cellular pixel resolution, thereby hindering the identification of cell-type-specific spatial patterns and gene expression variation.
To addre(More)